tags:
- NetworksEndianness
在不同的计算机体系结构中,对于数据的存储可能是不一样的。当下各种不同的体系结构提供了两种字节存储机制:大端和小端。在计算机的硬件实现上,采用这两种不统一的实现方式可能会为我们带来很多麻烦,比方说两台计算机的交流问题。所以我们规定了网络字节序为大端序。
1. Big Endian
大端序和小端序最大的区别就是 MSB(Most Significant Bit/Byte) 和 LSB(Least Significant Bit/Byte) 的所在位置。比方说我们有十六进制整数0x12345678,这里面 MSB(byte) 就是0x12,LSB 就是0x78。这很好理解,因为0x12是对结果影响最大的(即Most significant),而0x78是对结果影响最小的(Least significant)。
再往深了看,在0x12字节中,它的二进制形式为 0001 0010 最左边的 1 就是 MSB(bit)。而在0x78字节中,它的二进制形式为 0111 1000 最右边的 0 就是 LSB(bit)。
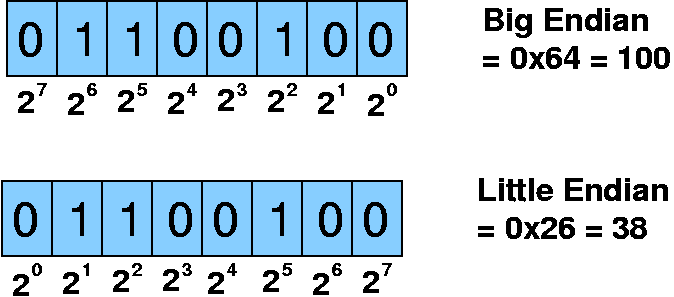
理解了这个概念,我们回头来看大小端分别都是什么。大端序规定 MSB 存储在低地址,传输数据时先传输 MSB 。小端序呢?我们往下看。
2. Little Endian
理解了 MSB、LSB 和大端序,理解小端序就易如反掌了。我们可以假设小端序将 MSB 存储在高地址,并在传输数据时先传输 LSB。事实也确实是这样的。
3. Big Endian vs. Little Endian
大小端各有其优缺点,有些人认为大端序方便阅读,因为符合人类书写的习惯。而我觉得大端序很反人类,反而随着地址的增加、位权也随之增加的小端序更易被我理解。在数据的处理上,由于计算机处理数据常常从低地址走向高地址。所以在比较大小(位数相同)、符号位的判断上面,大端序占优。而检查奇偶、比较大小(位数不同)、类型转换等计算密集型操作上小端序则更占优势。
4. How To Know?
怎么才能判断系统的大小端?
#include <stdio.h>
int main() {
int num = 1;
if (*(char *)&num == 1) {
printf("Little-endian\n");
} else {
printf("Big-endian\n");
}
return 0;
}